本文从零实现一个大模型,用于帮助理解大模型的基本原理,本文是一个读书笔记,内容来自于Build a Large Language Model (From Scratch)
目录
本系列包含以以下主题,当前在主题二
1. 文本处理
2. 注意力机制
3. 开发一个Transform架构的大模型
4. 使用无标记数据预训练模型
5. 分类微调
6. 指令微调
注意力机制
注意力机制是Transformer架构中一种技术,目的是能够将一个长序列中每个位置上元素都能和其他位置上的元素产生关联。
不含可训练权重的简单自注意力机制
为了充分理解自注意力机制的原理,我们从简单的自注意力机制开始。
要获得上下文向量,需要使用使用输入向量乘以注意力权重,大致过程如下:
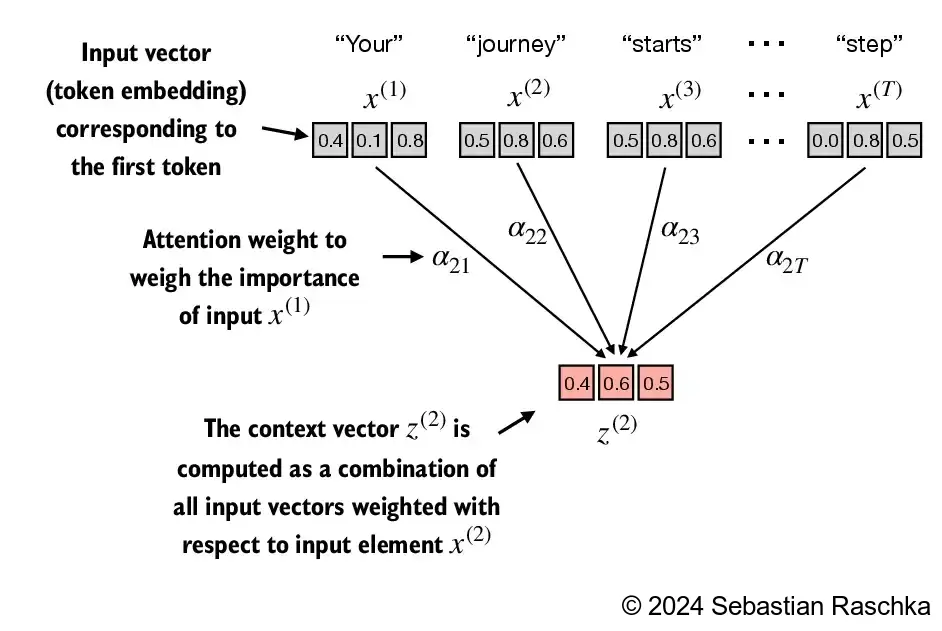
计算注意力评分
想要得到注意力权重,首先第一步要获取注意力评分,单个输入的注意力评分的计算过程如下:
1 | import torch |
1 | query = inputs[1] # 以第二个输入为例 |
tensor([0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865])
以上计算的本质就是其他六个单词相对于第二个单词“journey”注意力分数,所有他的长度是6,即inputs的总长度。
计算注意力权重
通过上一步计算得到注意力分数之后,第二部需要计算得到注意力权重只需要将注意力分数进行序列化(或者叫归一化),即可得到注意力权重,注意力权重的特点是总和为1
1 | attn_weights_2_tmp = attn_scores_2 / attn_scores_2.sum() |
Attention weights: tensor([0.1455, 0.2278, 0.2249, 0.1285, 0.1077, 0.1656])
Sum: tensor(1.0000)
以上演示了的到注意力权重的大致过程,现实中我们可以直接torch库提供的现成函数softmax计算注意力权重
1 | attn_weights_2 = torch.softmax(attn_scores_2, dim=0) |
Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
Sum: tensor(1.)
计算上下文向量
第三步计算上下文向量,将上面的到的注意力权重和某个token ID的嵌入向量相乘即可得到改token ID的上下文向量,注意经过计算之后,得到的这个上下文向量的维度和input的token ID向量的维度是相同的,即“journey”的上下文向量和“journey”的嵌入向量的维度是相同的。
1 | query = inputs[1] # 以第二个输入为例 |
tensor([0.4419, 0.6515, 0.5683])
以上过程只是计算了单个输入的上下文向量,LLM中需要为所有的输入都计算上下文向量
计算所有输入的上下文向量
了解了单个上下文向量的计算过程之后,我们可以为所有的输入计算上下文向量:
1 | # 1.计算注意力分数 |
tensor([[0.4421, 0.5931, 0.5790],
[0.4419, 0.6515, 0.5683],
[0.4431, 0.6496, 0.5671],
[0.4304, 0.6298, 0.5510],
[0.4671, 0.5910, 0.5266],
[0.4177, 0.6503, 0.5645]])
实现一个包含可训练权重的自注意力机制
可训练权重的自注意力机制的过程和上面的过程类似,也需要为特定的输入token计算上下文向量,区别是它引入了一个新的权重指标,他会在模型训练的过程中更新。这种可训练的权重指标对LLM来说至关重要,他可以使模型通过不断的学习生成更好的上下文向量。
权重指标分别是
- Query vector:
- Key vector:
- Value vector:
接下来仍然使用单词“journey”作为示例演示这个计算过程
1 | x_2 = inputs[1] # 第二个单词“journey” |
计算
1 | torch.manual_seed(123) |
计算Query、Key、Value向量:
1 | query_2 = x_2 @ W_query |
tensor([0.4306, 1.4551])
上面的示例演示了单个输入的Q、K、V向量,为所有输入计算也很简单:
1 | keys = inputs @ W_key |
keys.shape: torch.Size([6, 2])
values.shape: torch.Size([6, 2])
得到QKV向量之后,就可以计算注意力分数了,
1 | keys_2 = keys[1] # 计算第二个单词的注意力分数 |
tensor(1.8524)
1 | attn_scores_2 = query_2 @ keys.T # 为所有的输入计算注意力分数 |
tensor([1.2705, 1.8524, 1.8111, 1.0795, 0.5577, 1.5440])
第三步和上面一样,使用softmax函数将注意力分数序列化,得到注意力权重,注意力权重的总和是1。和前面的区别是进行缩放,将值除以输入维度的平方根。
1 | d_k = keys.shape[1] #input的维度 |
tensor([0.1500, 0.2264, 0.2199, 0.1311, 0.0906, 0.1820])
最后一步,计算上下文向量
1 | context_vec_2 = attn_weights_2 @ values |
tensor([0.3061, 0.8210])
实现自注意力类
将以上代码整理后,即可实现一个自注意力的类
1 | import torch.nn as nn |
tensor([[-0.0739, 0.0713],
[-0.0748, 0.0703],
[-0.0749, 0.0702],
[-0.0760, 0.0685],
[-0.0763, 0.0679],
[-0.0754, 0.0693]], grad_fn=<MmBackward0>)
上面的代码实现中使用nn.Linear替换了nn.Parameter(torch.rand(…),因为该方法有更好的权重初始化原型,会让模型的训练更稳定
实现因果自注意力机制
在因果自注意力机制中,对角线上面的词需要使用遮罩掩盖掉,这是为了在使用注意力评分计算上下文向量时,模型不能使用后面的词来参与计算,而只能使用某个词之前的输入进行计算。换句话说LLM只能根据已经生成的输出来计算下一次的输出。如下图所示
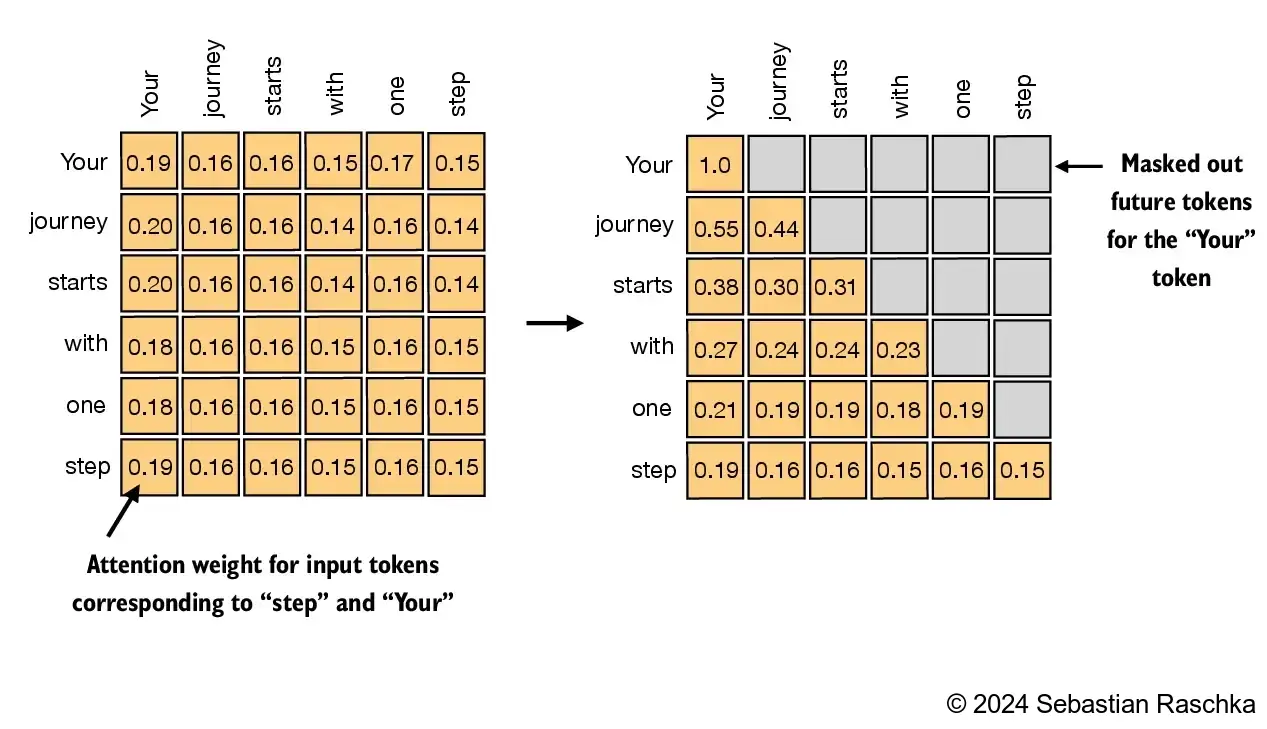
接下来如何用代码实现mask机制
1 | queries = sa_v2.W_query(inputs) |
tensor([[0.2899, -inf, -inf, -inf, -inf, -inf],
[0.4656, 0.1723, -inf, -inf, -inf, -inf],
[0.4594, 0.1703, 0.1731, -inf, -inf, -inf],
[0.2642, 0.1024, 0.1036, 0.0186, -inf, -inf],
[0.2183, 0.0874, 0.0882, 0.0177, 0.0786, -inf],
[0.3408, 0.1270, 0.1290, 0.0198, 0.1290, 0.0078]],
grad_fn=<MaskedFillBackward0>)
1 | attn_weights = torch.softmax(masked / keys.shape[-1]**0.5, dim=-1) # 计算注意力权重 |
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],
[0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],
[0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],
[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
grad_fn=<SoftmaxBackward0>)
增加dropout参数
在实际中,为了防止模型在训练时过拟合,还需要随机丢弃一些值,dropout可以在以下时机:
- 在计算上下文权重之后,随机丢弃一些值
- 在计算上下文向量之后,随机丢弃一些值
比较常见的方式是第一种。如下图所示的dropout值为50%
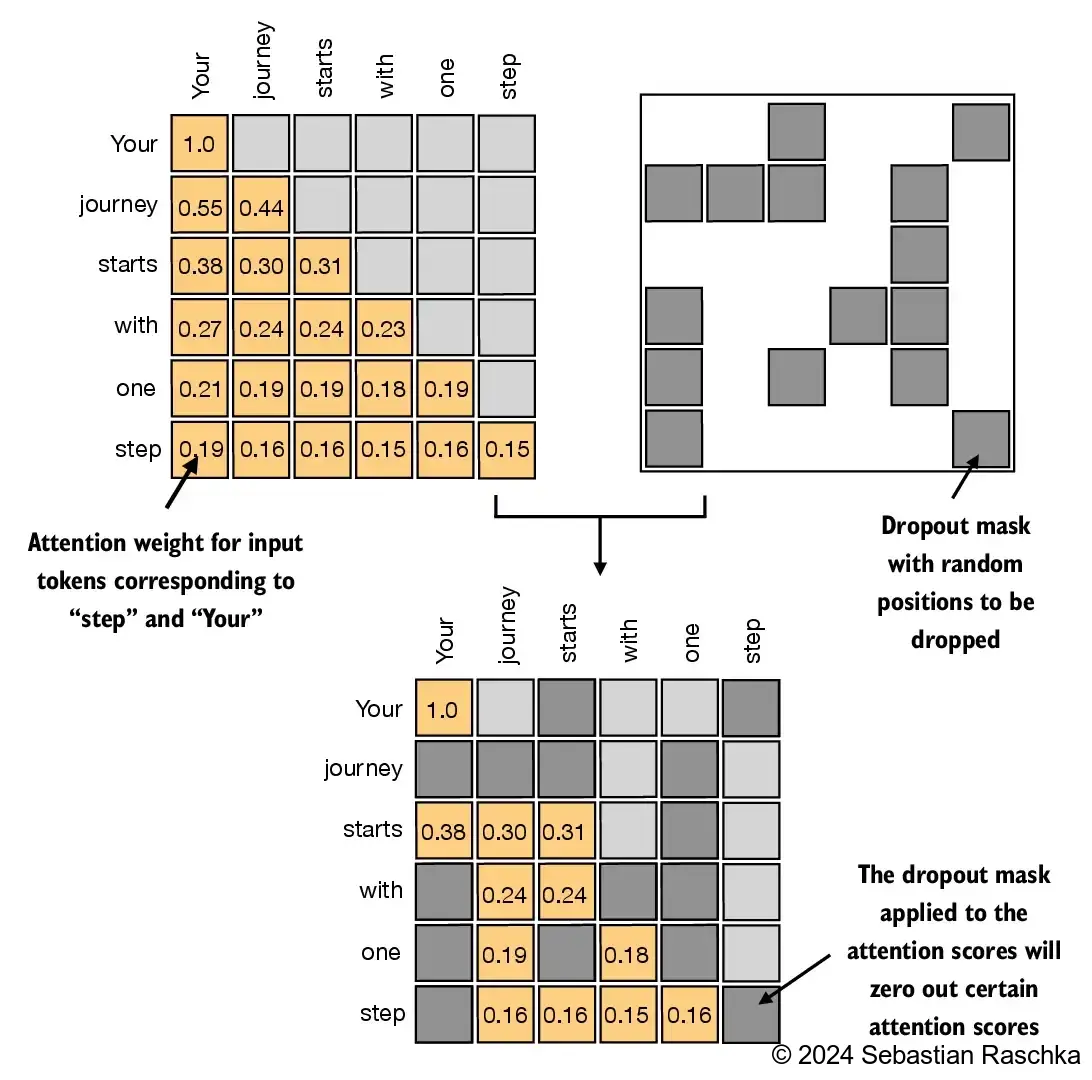
代码的实现也很简单
1 | torch.manual_seed(123) |
tensor([[2.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.7599, 0.6194, 0.6206, 0.0000, 0.0000, 0.0000],
[0.0000, 0.4921, 0.4925, 0.0000, 0.0000, 0.0000],
[0.0000, 0.3966, 0.0000, 0.3775, 0.0000, 0.0000],
[0.0000, 0.3327, 0.3331, 0.3084, 0.3331, 0.0000]],
grad_fn=<MulBackward0>)
实现因果自注意力类
然后实现一个因果自注意力类,它包含mask和dropout机制
1 | import torch.nn as nn |
1 | x_2 = inputs[1] # second input element |
tensor([[[-0.4519, 0.2216],
[-0.5874, 0.0058],
[-0.6300, -0.0632],
[-0.5675, -0.0843],
[-0.5526, -0.0981],
[-0.5299, -0.1081]],
[[-0.4519, 0.2216],
[-0.5874, 0.0058],
[-0.6300, -0.0632],
[-0.5675, -0.0843],
[-0.5526, -0.0981],
[-0.5299, -0.1081]]], grad_fn=<UnsafeViewBackward0>)
context_vecs.shape: torch.Size([2, 6, 2])
将单头注意力拓展为多头注意力
多头注意力和核心思想是将单个注意力重复多次
1 | class MultiHeadAttention(nn.Module): |
1 | torch.manual_seed(123) |
tensor([[[0.3190, 0.4858],
[0.2943, 0.3897],
[0.2856, 0.3593],
[0.2693, 0.3873],
[0.2639, 0.3928],
[0.2575, 0.4028]],
[[0.3190, 0.4858],
[0.2943, 0.3897],
[0.2856, 0.3593],
[0.2693, 0.3873],
[0.2639, 0.3928],
[0.2575, 0.4028]]], grad_fn=<ViewBackward0>)
context_vecs.shape: torch.Size([2, 6, 2])