本文从零实现一个大模型,用于帮助理解大模型的基本原理,本文是一个读书笔记,内容来自于Build a Large Language Model (From Scratch)
目录
本系列包含以以下主题,当前在主题一
1. 文本处理
2. 注意力机制
3. 开发一个Transform架构的大模型
4. 使用无标记数据预训练模型
5. 分类微调
6. 指令微调
处理文本
LLM模型首先要处理文本,处理文本的目标是将文本转换成高维度的嵌入向量,具有相关性的文本的距离是相近的。高维度坐标无法掩饰,这里使用二维的坐标做演示,具有相似属性的文本在二维的平面坐标系里考的更近。
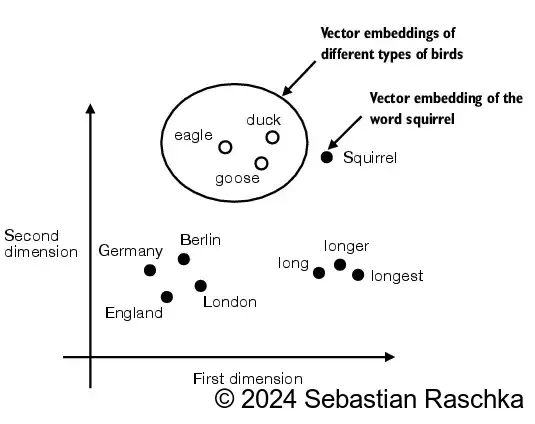
但是二维的向量所能包含的信息太少了,LLM通常使用上千维度的向量,这也是LLM消耗硬件资源的原因之一。
分词器 Tokenizer
在处理文本之前需要将,需要使用分词器将文本分割成更小的单元,比如英文句子中的单词和标点符号
以下代码将一篇txt格式的短篇小说划分成单词和标点符号,我们称之为token。
1 | import re |
Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no
将token去重后组成一个词库vocab,词库中的每个元素都有一个唯一个ID,称之为token ID
1 | preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text) |
1130
1 | for i, item in enumerate(vocab.items()): |
('!', 0)
('"', 1)
("'", 2)
('(', 3)
(')', 4)
(',', 5)
('--', 6)
('.', 7)
(':', 8)
(';', 9)
('?', 10)
('A', 11)
('Ah', 12)
('Among', 13)
('And', 14)
('Are', 15)
('Arrt', 16)
('As', 17)
('At', 18)
('Be', 19)
('Begin', 20)
('Burlington', 21)
('But', 22)
('By', 23)
('Carlo', 24)
('Chicago', 25)
('Claude', 26)
('Come', 27)
('Croft', 28)
('Destroyed', 29)
('Devonshire', 30)
('Don', 31)
('Dubarry', 32)
('Emperors', 33)
('Florence', 34)
('For', 35)
('Gallery', 36)
('Gideon', 37)
('Gisburn', 38)
('Gisburns', 39)
('Grafton', 40)
('Greek', 41)
('Grindle', 42)
('Grindles', 43)
('HAD', 44)
('Had', 45)
('Hang', 46)
('Has', 47)
('He', 48)
('Her', 49)
('Hermia', 50)
使用上面的词库,将下面的文本转换为token ID:
1 | tokenizer = SimpleTokenizerV1(vocab) |
[1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7]
1 | tokenizer.decode(ids) # 将token ID转化为文本 |
'" It\' s the last he painted, you know," Mrs. Gisburn said with pardonable pride.'
使用上面的方法无法处理词库里没有的单词,所以我们使用占位符来处理不认识的单词,修改上面的代码如下:
1 | class SimpleTokenizerV2: |
1 | all_tokens = sorted(list(set(preprocessed))) |
1132
可以看到词库拓展了两个新的token,分别为<|endoftext|>和<|unk|>,词库中不存在的token会被转化为<|unk|>,token ID是1131
1 | for i, item in enumerate(list(vocab.items())[-5:]): |
('younger', 1127)
('your', 1128)
('yourself', 1129)
('<|endoftext|>', 1130)
('<|unk|>', 1131)
1 | tokenizer = SimpleTokenizerV2(vocab) |
Hello, do you like tea? <|endoftext|> In the sunlit terraces of the palace.
1 | tokenizer.encode(text) |
[1131, 5, 355, 1126, 628, 975, 10, 1130, 55, 988, 956, 984, 722, 988, 1131, 7]
1 | tokenizer.decode(tokenizer.encode(text)) |
'<|unk|>, do you like tea? <|endoftext|> In the sunlit terraces of the <|unk|>.'
BPE字节对编码
上面的例子为了演示,直接采用了比较简单的策略进行分词,实际过程中并不会采用这种方式,GPT2使用了字节对编码作为分词器(BytePair encoding,简称BPE),该分词器会将文本分割成更小的单元,如unfamiliarword别分割成[“unfam”, “iliar”, “word”]
分词器的原理可以参考这里,本文使用了OpenAI使用Rust实现的开源库tiktoken,它有好的的性能。
使用tiktoken处理同样的文本的结果如下:
1 | import tiktoken |
[15496, 11, 466, 345, 588, 8887, 30, 220, 50256, 554, 262, 4252, 18250, 8812, 2114, 1659, 617, 34680, 27271, 13]
1 | strings = tokenizer.decode(integers) |
Hello, do you like tea? <|endoftext|> In the sunlit terracesof someunknownPlace.
使用滑动窗口处理数据样本
LLM每次生成一个词,所以在训练时我们需要预处理文本,处理方式如下图,红色的是目标值,蓝色的试输入值。这种方法称为滑动窗口。

1 | with open("the-verdict.txt", "r", encoding="utf-8") as f: |
5145
1 | enc_sample = enc_text[50:] |
x: [290, 4920, 2241, 287]
y: [4920, 2241, 287, 257]
上面的代码如下图所示,蓝色的是输入,红色的目标
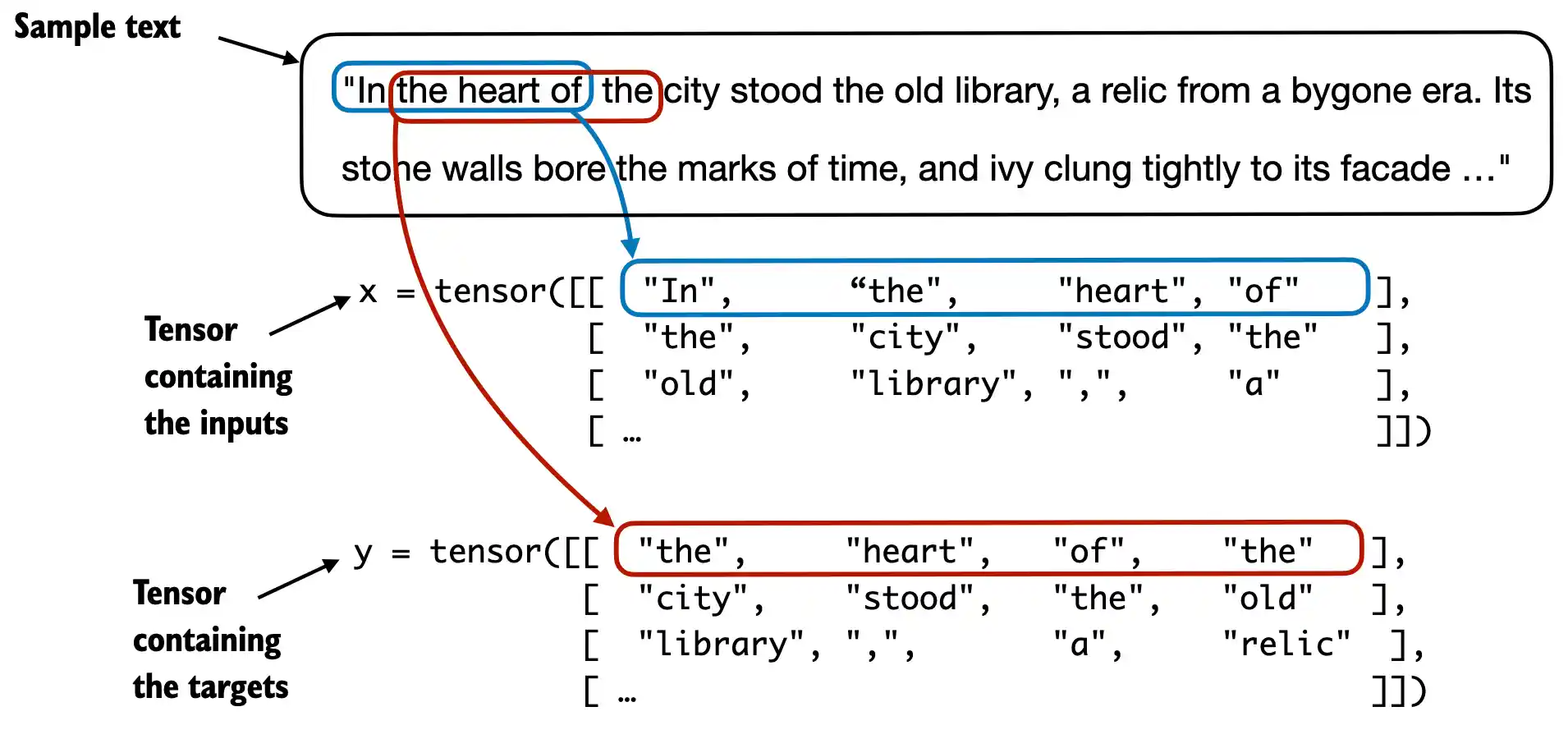
1 | for i in range(1, context_size+1): |
[290] ----> 4920
[290, 4920] ----> 2241
[290, 4920, 2241] ----> 287
[290, 4920, 2241, 287] ----> 257
1 | for i in range(1, context_size+1): |
and ----> established
and established ----> himself
and established himself ----> in
and established himself in ----> a
接下来构建一个类来处理训练数据集,先使用分词器处理输入的文本数据,将他们转换为token id,然后使用滑动窗口的策略将数据输入数据input_ids和目标数据target_ids。
1 | import torch |
1 | with open("the-verdict.txt", "r", encoding="utf-8") as f: |
Inputs:
tensor([[ 40, 367, 2885, 1464],
[ 367, 2885, 1464, 1807],
[ 2885, 1464, 1807, 3619],
[ 1464, 1807, 3619, 402],
[ 1807, 3619, 402, 271],
[ 3619, 402, 271, 10899],
[ 402, 271, 10899, 2138],
[ 271, 10899, 2138, 257]])
Targets:
tensor([[ 367, 2885, 1464, 1807],
[ 2885, 1464, 1807, 3619],
[ 1464, 1807, 3619, 402],
[ 1807, 3619, 402, 271],
[ 3619, 402, 271, 10899],
[ 402, 271, 10899, 2138],
[ 271, 10899, 2138, 257],
[10899, 2138, 257, 7026]])
1 | # 滑动窗口的步长为4时 |
Inputs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Targets:
tensor([[ 367, 2885, 1464, 1807],
[ 3619, 402, 271, 10899],
[ 2138, 257, 7026, 15632],
[ 438, 2016, 257, 922],
[ 5891, 1576, 438, 568],
[ 340, 373, 645, 1049],
[ 5975, 284, 502, 284],
[ 3285, 326, 11, 287]])
上面步长stride为1和4的示意图如下:
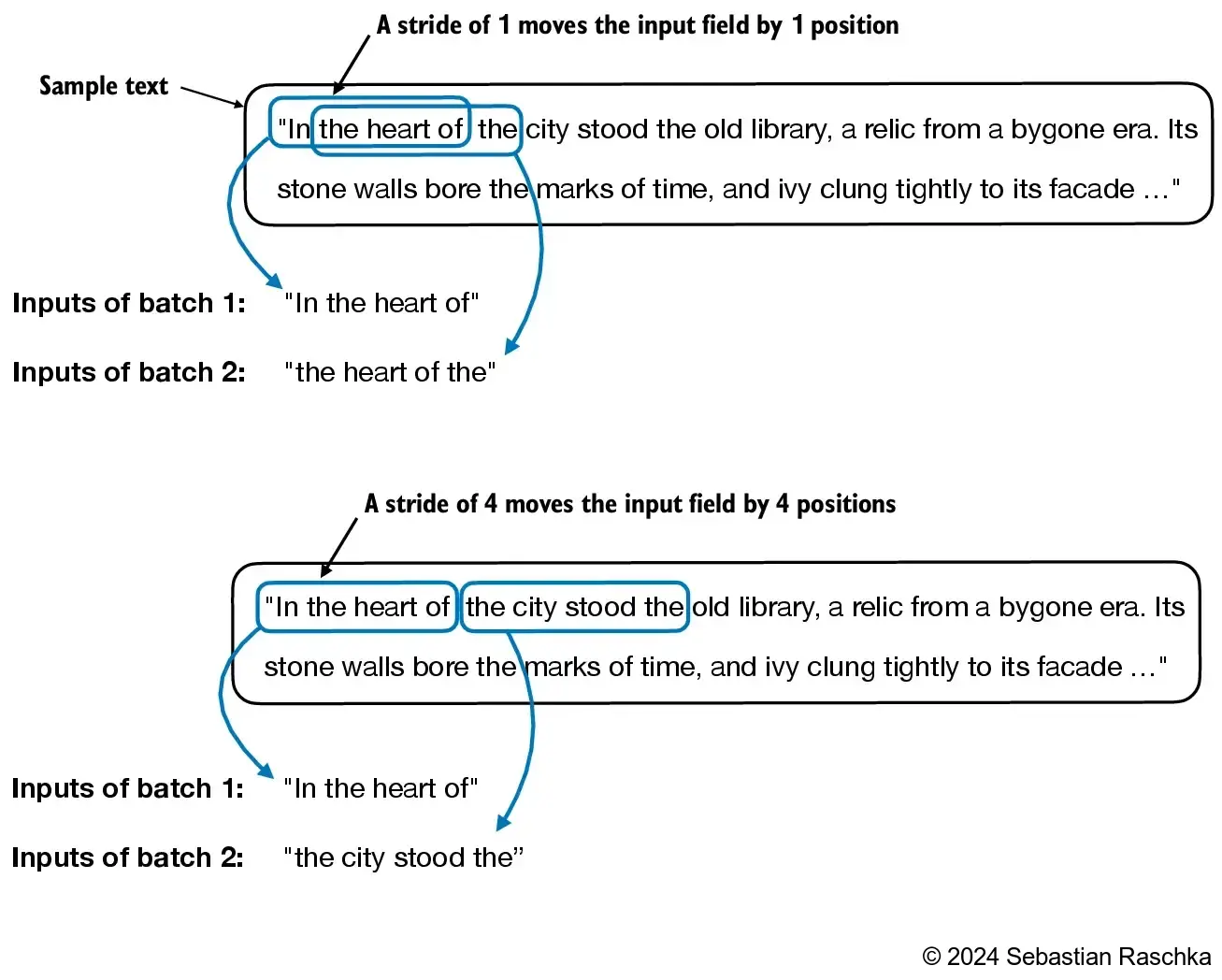
创建嵌入向量
将数据分成输入值和目标值之后,接下来的步骤就是要token ID转化为向量以便LLM做后续处理,这个步骤称之为嵌入层
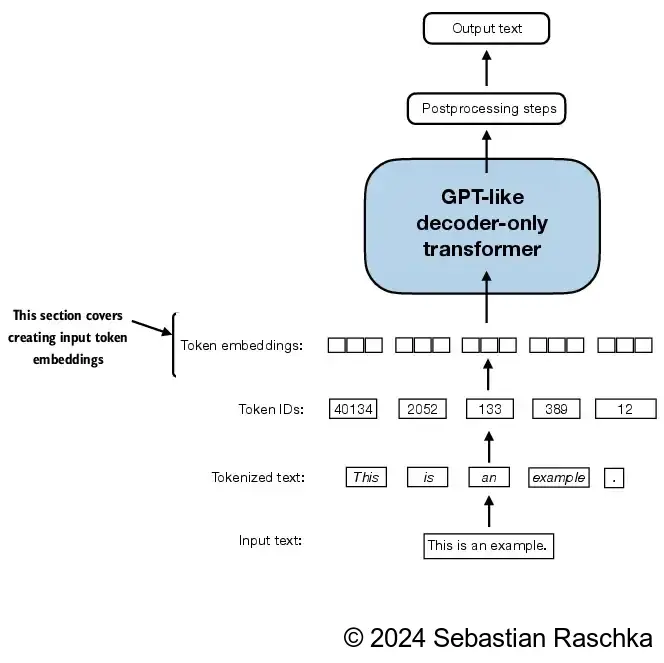
将token ID转化为向量可以使用torch.tensor方法,下面是一个示例:
1 | import torch |
Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)
tensor([[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-2.8400, -0.7849, -1.4096],
[ 0.9178, 1.5810, 1.3010]], grad_fn=<EmbeddingBackward0>)
可以看到嵌入层是二维向量,长度为6,每个元素都是一个三维的向量,使用嵌入层处理输入值后,是一个长度为4的二维向量,每个token ID都被转换为一个三维向量。
位置编码
上面将token ID转化成嵌入向量时,没有包含子词的位置信息,同一个单词在句子的不同位置所代表的含义可能是不同的,所以我们还需要把token ID的位置信息也加入到向量中。
1 | # 创建嵌入层 |
torch.Size([8, 4, 256])
以上结果表明inputs有8个批次的数据,每个批次有4个token,每个token被转换成一个256纬度的向量
接下来获取位置向量
1 | # 处理位置向量 |
torch.Size([4, 256])
为了简单起见,这里简单的将toke ID的向量和位置向量相加得到最终的输入向量
1 | input_embeddings = token_embeddings + pos_embeddings |
torch.Size([8, 4, 256])
这样我们就得到了嵌入向量,完整的代码如下,后面我们要使用这个类处理所有的输入数据。
1 | import tiktoken |
1 | for batch in dataloader: |
1 | print(input_embeddings.shape) |
torch.Size([8, 4, 256])