前言
PWA(Progressive Web Apps)即渐进式网络应用程序,由于其出色的用户体验,正在变得越来越流行。如果你有留意,一些大厂项目如百度云盘,阿里云官网等已经采用了PWA方案。这篇文章我们先介绍PWA应用的基础理论——Service Worker。
浏览器缓存机制
Service Worker本质上也是浏览器内一个重要的缓存技术,所以在讲解Service Worker之前,我们还是有必要了解一下浏览器所提供的所有缓存技术,对他们的优先级规则和原理有一个大致的了解。不过一提到浏览器缓存,大家比较熟知的是通过HTTP的响应头来实现的HTTP缓存也称Disk缓存,但浏览器的缓存机制并不仅限于此,按照他们的种类和优先级从高到低可分为四种:Memory Cache,Service Worker,HTTP Cache,Push Cache。下面对他们做一个简单的总结:
Memory Cache顾名思义,就是从内存中读取缓存,从内存中读取虽然快,但只是一种短期缓存策略,比如短时间内刷新一个页面,浏览器会直接从内存中读取缓存。不过由于该缓存策略没有具体的文档规范,所以各家浏览器的实现策略不尽相同,并且它不能由开发人员进行干预,只能由浏览器内置的策略来维护缓存,所以在实际项目中我们不需要关注它。HTTP Cache是我们比较熟知的,通过特定的HTTP协议响应头控制,如Expire,Since-Last-Modify,Cache-Control,ETag等,以实现强缓存或协商缓存。这种方式是目前比较流行的缓存方式,通过Webpack,Gulp等打包工具可以很容易实现,以提高应用的性能。Push Cache依赖于HTTP2新特性:服务端推送。Service Worker是我们今天要讲的主角,它比HTTP缓存有更强大特性,正在被越来越多的应用于实际项目中,它允许开发人员通过代码精确控制缓存文件,并且优先级高于HTTP缓存,他像拦截器一样工作在浏览器和服务器之间,浏览器发出的任何请求都能被他感知到,Service Worker不仅能拦截HTTP请求,更准确的说它提供了强大的离线应用功能,他的设计理念是离线优先,也提供如推送通知,后台定时同步等其他强大的特性,但本文只介绍网络请求拦截功能,这是Service Worker做数据缓存的基础。
由于Service Worker是一个工作在浏览器主线程之外的Worker线程中的脚本文件,所以它不能直接操作DOM元素。
Service Worker生命周期
理解Service Worker最重要的就是理解它的生命周期、生命周期各个阶段所触发的事件以及在各个阶段我们要做什么样的事情。其生命周期主要分为以下几个阶段。
1. 注册Service Worker
注册Service Worker的工作需要在页面主线程中完成,比如body标签结束之前。
1 | if ('serviceWorker' in navigator) { |
这段代码很简单,首先检查serviceWorker属性是否可用,如果可用,则在window.onlond事件里注册一个service-worker.js脚本。每次在页面加载完之后这段代码都会执行,但是你不必担心重复注册,浏览器会知道你的站点是否已经注册过Serice Worker。第一次注册成功之后,Service Worker会存储在用户的浏览器中,关闭页面之后它会处于休眠状态,直到用户再次打开该站点,才会被重新唤起。
这里还有一点需要说明,我们的service-worker.js是注册在域名的根目录下即/,这意味着你可以在service-worker.js的fetch事件里,捕获到域名下所有的网络请求。换句话说,如果你的文件路径是/module/service-worker.js,那么你只能在你的脚本里处理以/module为开头的网络请求,比如/module/app.js。
另外,上面讲过Service Worker不能操作DOM元素,所以其本身并强制要求注册在window.onload事件里,但这么做是符合最佳实践的,这篇文章详细解释了这么做的原因。
2. 安装Service Worker
Service Worker注册成功之后,接下来会自动触发安装事件(install),并且包括安装在内的所有后续事件都发生在worker线程中,即刚刚注册的service-worker.js文件中,下面是install示例代码:
1 | const CACHE_NAME = 'v1'; |
install事件是Service Worker执行的第一个事件,同一个Service Worker只会调用一次,即使你的Service Worker脚本文件只有一个字节不同,浏览器也将视为一个新的Service Worker。如例所示,在install阶段,我们一般处理与缓存的相关工作,例如开辟缓存空间、添加缓存等。
在这段代码中,我们看到了很多新的面孔,我们来一一解释他们:
self: 这是Service Worker中特有的全局对象,类似与主线程中的window对象。event.waitUntil: 该函数接受一个Promise对象,它告诉Service Worker,内部的Promise对象没有resolve之前,缓存工作就还没有完成,安装阶段也就没有完成,并且不应该转移到下一个阶段。caches:CacheStroge对象,它用来控制缓存相关的工作,caches对象的很多方法都是异步的,会返回一个Promise对象,更多详细的API可以参考这里。
3. 激活Service Worker
Service Worker安装成功之后,会触发activate事件,在这个阶段我们一般做一些清理旧缓存相关的工作,稍后你会理解我们为什么会在这个阶段清理缓存,以下是一段简单的示例代码:
1 | self.addEventListener('activate', event => { |
4. Service Worker接管页面
在activate事件之后,Service Worker开始接管页面,被接管页面的任何网络请求,都会触发fetch事件,在fetch事件里,我们一般去检查缓存是否命中,如果命中则直接返回缓存,否则调用fetch方法发起网络请求,而按照上面提到的缓存优先级顺序,此时浏览器会去检查HTTP Cache。
1 | self.addEventListener('fetch', event => { |
需要说明的是,fetch事件只会在用户第二次打开页面或者刷新页面时触发,具体的原因,你可能认为这是由于我们是在window.onload事件注册的Service Worker,即注册事件发生在所有网络请求完成之后,所以才不会触发fetch事件,然而实际的原因并不是这样,这其实是由Service Worker本身的特性所决定的,因为它的理念是离线优先,这里有个例子能够很好的证明和解释Service Worker为什么故意这样设计。
Service Worker的这种特性导致了接管页面后触发的事件并不是发生在用户第一次打开该页面的时候,而是在用户第二次打开页面或者第一次打开页面再次刷新的时候,此时页面才真正处于被接管的状态,但这种默认的行为可以通过在activate事件的回调函数里调用clients.claim()方法来改变,使页面在第一次打开的时候就被接管,无需等到第二次打开或者刷新之后。
5. 更新Service Worker
任何缓存系统,缓存数据的过期和更新都是需要重点关注和解决的,Service Worker也不例外。随着业务逻辑的发展,我们必然会更新资源文件,比如上面例子中的app.js,相应地,我们也必须要更新缓存,而为了更新缓存,我们就必须要更新service-worker.js,前面说过,只要service-worker.js的内容发生了变化,浏览器都会认为这是一个全新的Service Worker,所以我们可以简单的修改service-worker.js文件的内容:const CACHE_NAME = 'v2'。更新过的Service Worker则会经历以下阶段:
- 再次触发的
install事件,安装新的缓存内容。此时,当前的页面仍然被v1版本的Service Worker托管,v2版本的Service Worker此时处于待激活状态(waiting to activate)。即页面加载的仍然是旧的缓存内容。 - 当用户完全关闭页面后(浏览器所有的tab都没有打开该站点),并再次打开页面或者点击当前页面上的链接导航到其他站点再返回该站点后才会触发activate事件,此时,v1版本的Service Worker才会停止(
stop),v2版本的Service Worder会正式接管(activate)页面,新的缓存文件才开始生效。这也是为什么我们把删除旧缓存的代码放在activate事件里,因为此时删除的缓存时v1版本的缓存。但这种行为也是可以改变的,可以通过在install事件里调用self.skipWaiting()来跳过这种等待激活的默认行为。
Service Worker只所以这样设计,是为了保证即使在多个tab都同时打开同一个站点或页面的时候,同一个时间也只有一个版本的Service Worker生效。这样就避免了多个tab打开同一个站点,但是不同tab会有不同版本缓存的现象。
这种特性导致即使只有一个tab打开了页面,也不能像第一次打开页面的时候,靠刷新来触发activate事件,这是由刷新的工作方式导致的。因为在刷新的时候,新的响应数据到达浏览器之前,旧的页面没有关闭,所以自始至终页面都处于打开状态,新版本的Service Worker也就不会激活。
演示代码
看到这里,你也许会认为Service Worker的整个过程有点难以理解,接下来我们用一个足够简单的例子来演示整个过程。
首先创建一个index.html,代码如下:
1 | <!doctype html> |
index.html文件加载另外三个文件,分别是app.css,cat.jpg,service-worker.js以及app.js文件,
为了保持例子足够简单并能够说明问题,app.css和app.js的内容分别如下:
1 | body { |
1 | document.body.append('app version: v1'); |
service-worker.js文件的内容如下:
1 | const CACHE_NAME = 'v1'; |
利用node的serve包我们可以很容易的在本地启动一个简单的静态服务器,在项目的根目录下执行serve ./
- 假设用户第一次访问我们的站点,打开页面:

查看控制台,可以看到register,install,activate事件均被触发,而fetch事件并没有触发:
当用户刷新页面或者第二次访问我们的站点,可以看到fetch事件被触发,查看控制台:

查看网络面板,也可以看到资源是从Service Worker加载,即缓存已生效。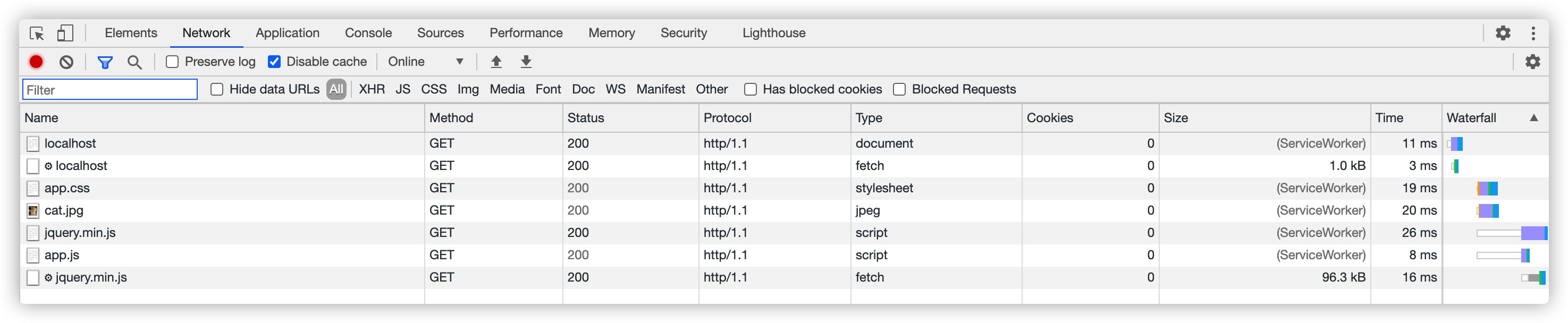
假设此时我们的站点发生了更新,更新app.js:
document.body.append('app version: v2');以及app.css:background-color: #7c8ae9;,由于资源文件更新,所以service-worker.js也要更新:const CACHE_NAME = 'v2';。此时我们的站点发生了更新,但假如用户再次打开页面或者刷新当前页面,他将仍然看到的老的页面:
查看开发者工具也可以看到新的Service Worker处于waiting to activate状态: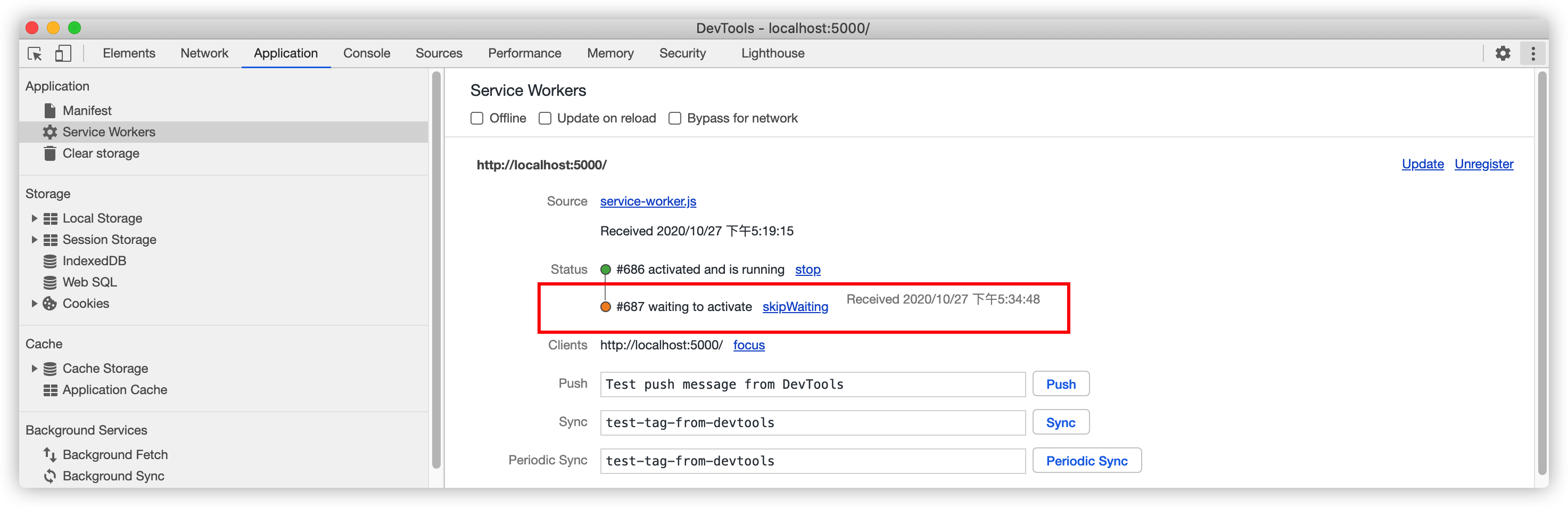
只有当用户完全关闭或离开站点,并再次访问我们的站点,新的Service Worker才会接管页面,页面也会展示更新过后的内容:

这种模式有点类似于浏览器的更新策略,比如你的Chrome浏览器提示你新的软件版本已经下载安装就绪了,但它提示你必须重新启动浏览器,才能使用新的版本。而在完全关闭浏览器之前,无论你再打开多少个浏览器窗口,你正在使用的都是老的版本。我们用一幅图来展示Service Worker生命周期的整个过程。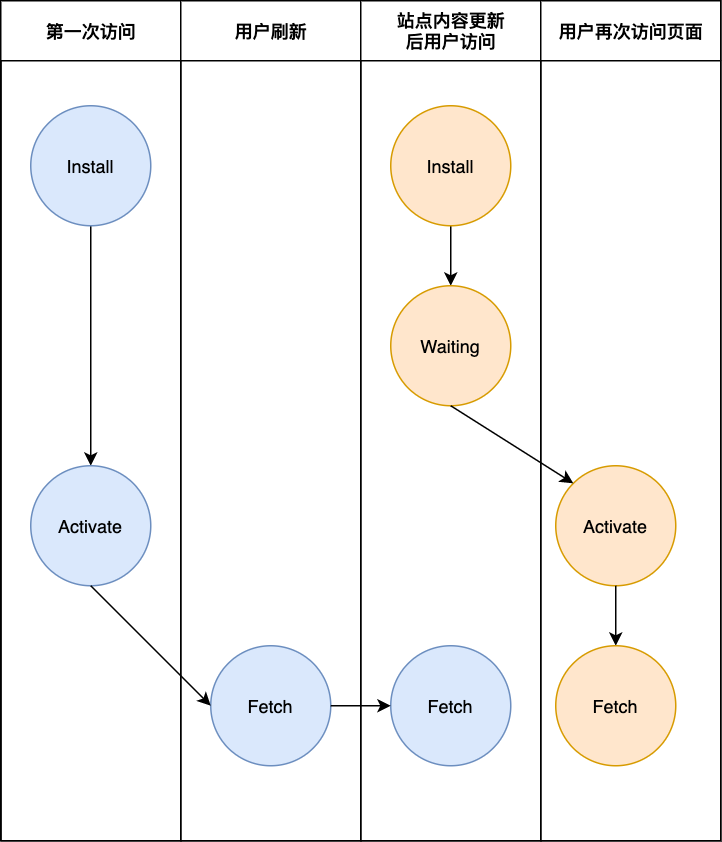
Service Worker的调试技巧级注意事项
上面调试Service Worker的时候,我们必须不断的打开,关闭浏览器,这给调试带来了诸多不便,但幸亏Chrome浏览器的开发者工具,为我们提供了设置项,是我们能很容易的调试Service Worker。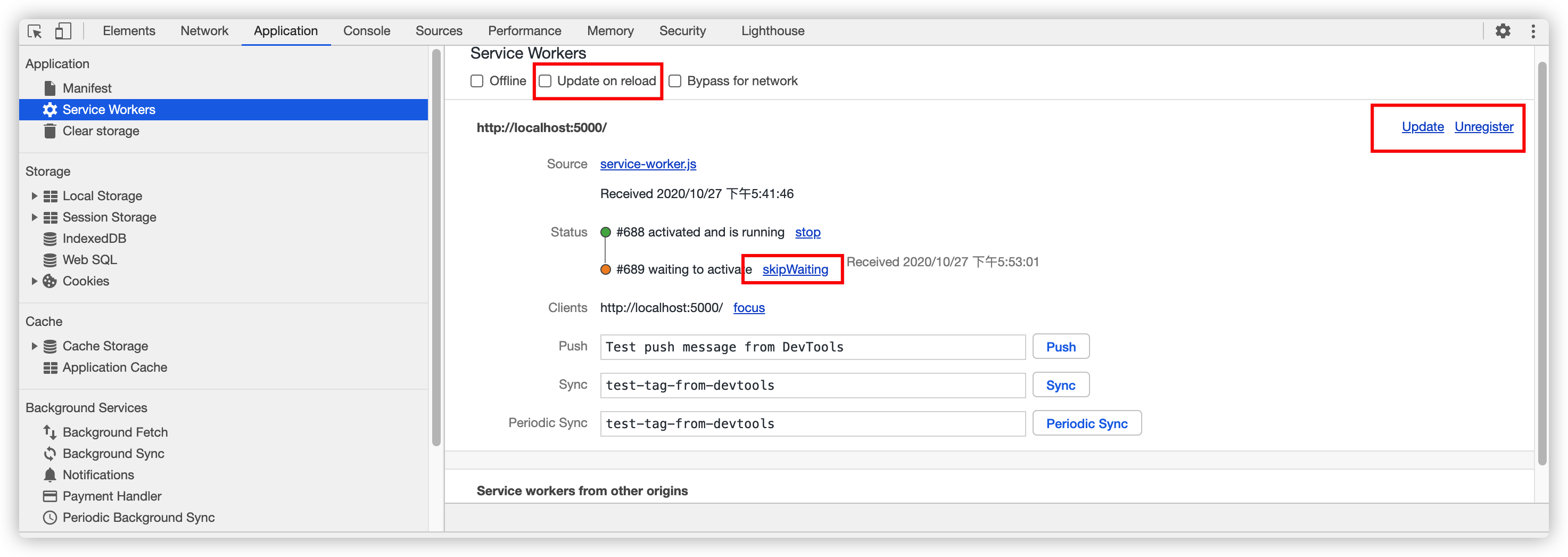
Update on reload可以使更改过的Service Worker脚本立刻接管页面,而不需要关闭当前Tab。skipWaiting也可以使当前处于待激活状态的Service Worker立即接管页面。Unregister选项则可以删除浏览器上已注册过的Service Worker
Service Worker在部署到生产环境之后必须使用HTTPS协议,HTTP只允许在本地开发时使用localhost。浏览器支持方面,Chrome, Firefox和Opera都已经支持,详细的支持列表点这里。